Your semantic layer gets outdated the moment someone asks a question it can't answer properly. A metric gets calculated wrong, a description is unclear, or someone needs a new aggregation that doesn't exist yet.
The usual solution? Submit a ticket to the data team, wait a few days, and pretend you can do your work just fine until it gets fixed.

Despite using this gif constantly on our Slack, we didn’t want to live it. So we started thinking: what if your semantic layer could learn in real-time?
That thought quickly turned into a new feature: the self-improving semantic layer. With this feature, Lightdash's AI can spot when your semantic layer needs an update and propose those changes in real time. Your semantic layer improves as your business changes, without waiting on your data team.
The problem with semantic layers
Semantic layers are supposed to be your single source of truth. They map your messy data warehouse tables to clean business concepts, so "revenue" means the same thing everywhere - in your BI tool, your notebooks, your product analytics, wherever.
In theory, this works great. But in reality, it’s maintenance hell.
Your data changes as your business changes, but your semantic layer stays frozen until someone manually updates it. That "someone" is usually a data engineer who's already drowning in work.
So semantic layers drift. Descriptions get stale and metrics that should exist don't, until eventually people start working around the semantic layer instead of trusting it (defeating the whole point of having one in the first place).
What if your semantic layer could fix itself?
To solve this problem, we built AI that can update your semantic layer while answering questions from your team.
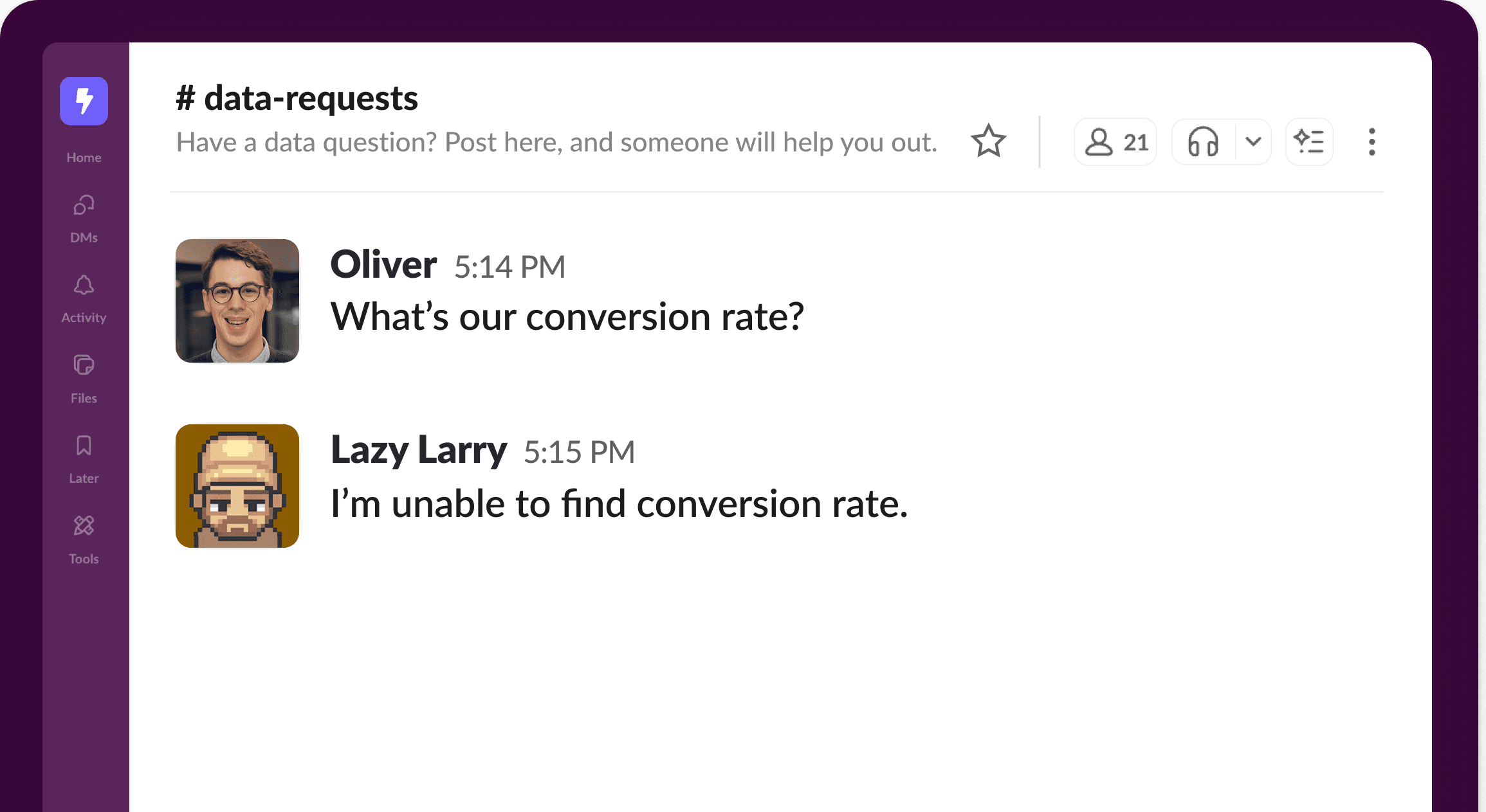
Let's say someone on your marketing team asks the agent, "What's our conversion rate?" The agent looks at your semantic layer and realizes there's no conversion rate metric defined.
A typical AI bot would say something like:
But our AI agents will:
Figure out how to calculate conversion rate from your existing data
Create a new metric in your semantic layer
Use that metric to answer the question
Track the change so you can review or revert it later
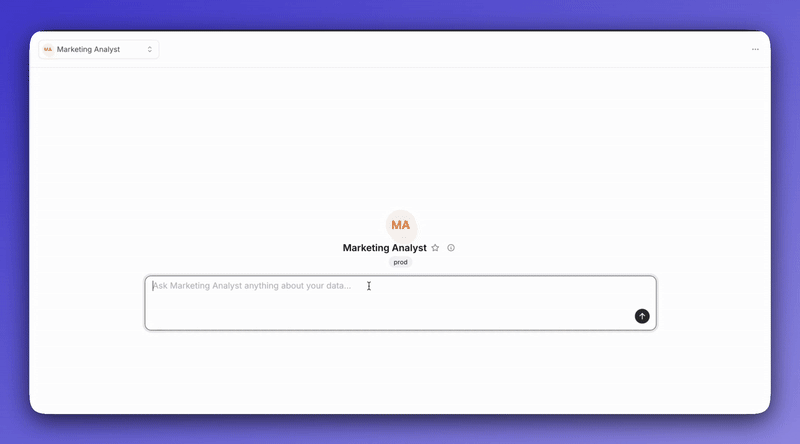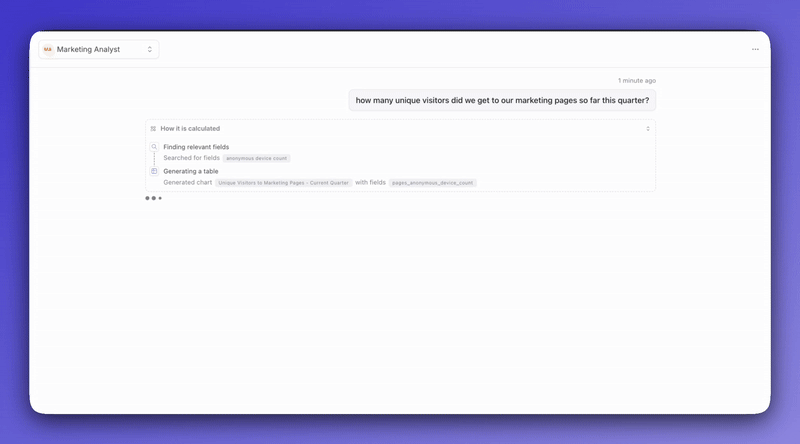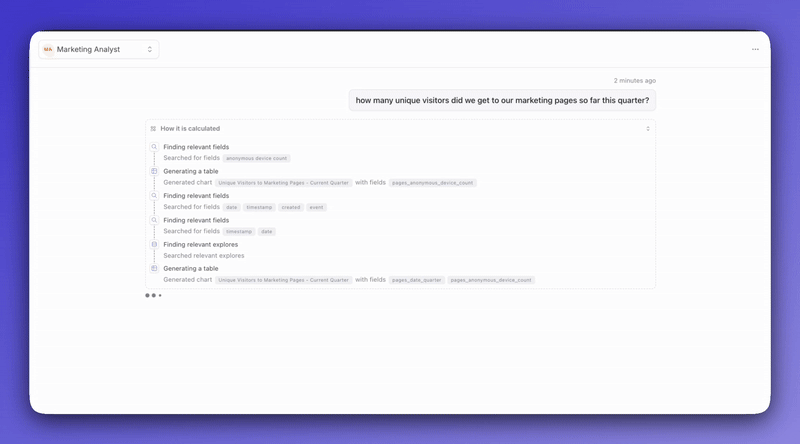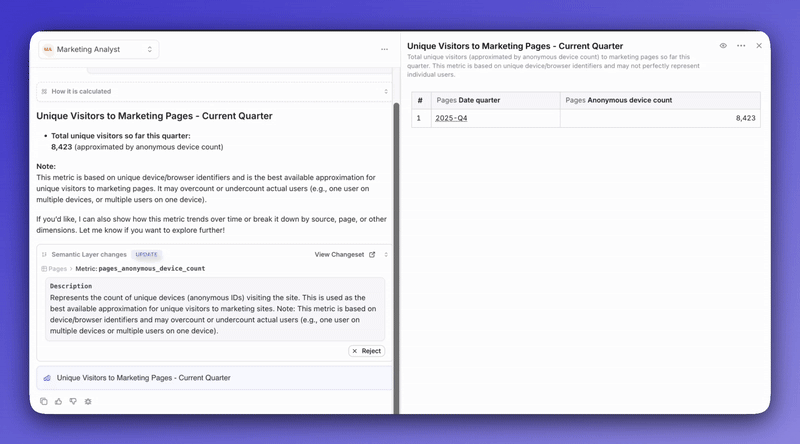
So you get something like:
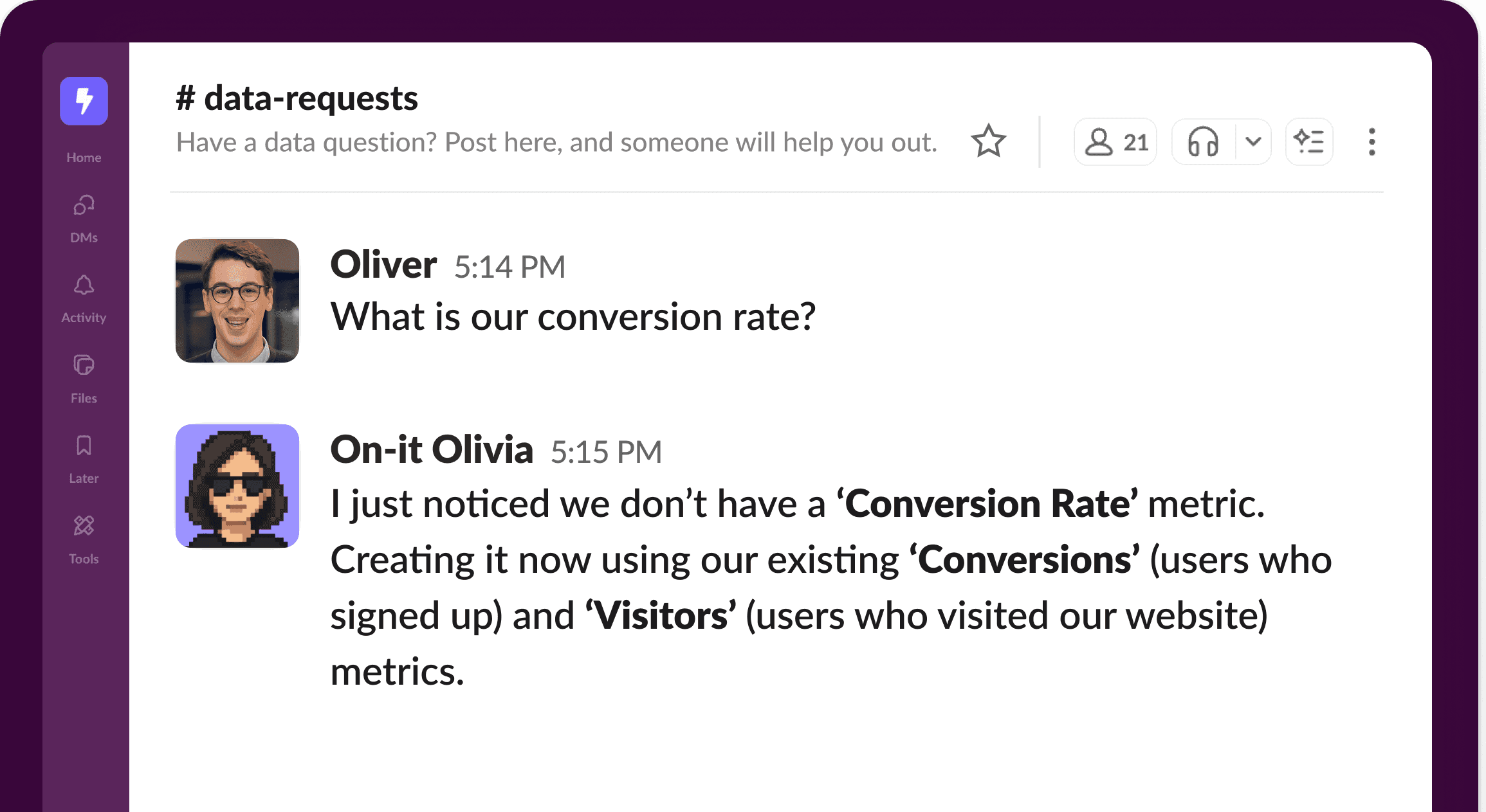
All of this happens during your conversation. No tickets, no waiting, and no context-switching for your data team.
How it actually works
When you enable self-improvement for an agent, here's what changes:
⚡ Real-time updates to descriptions
Agents refine field and metric descriptions as people ask questions, so your semantic layer stays current without manual cleanup.
⚡ New metrics from real conversations
When users ask for something new (“Can we track average deal size per region?”), agents can suggest new metrics derived from existing dimensions.
⚡ Everything tracked, nothing hidden
Every change is recorded in a changeset - a reviewable batch of proposed updates. You can see these in your Project Settings and admins can approve, reject, or revert with a click.
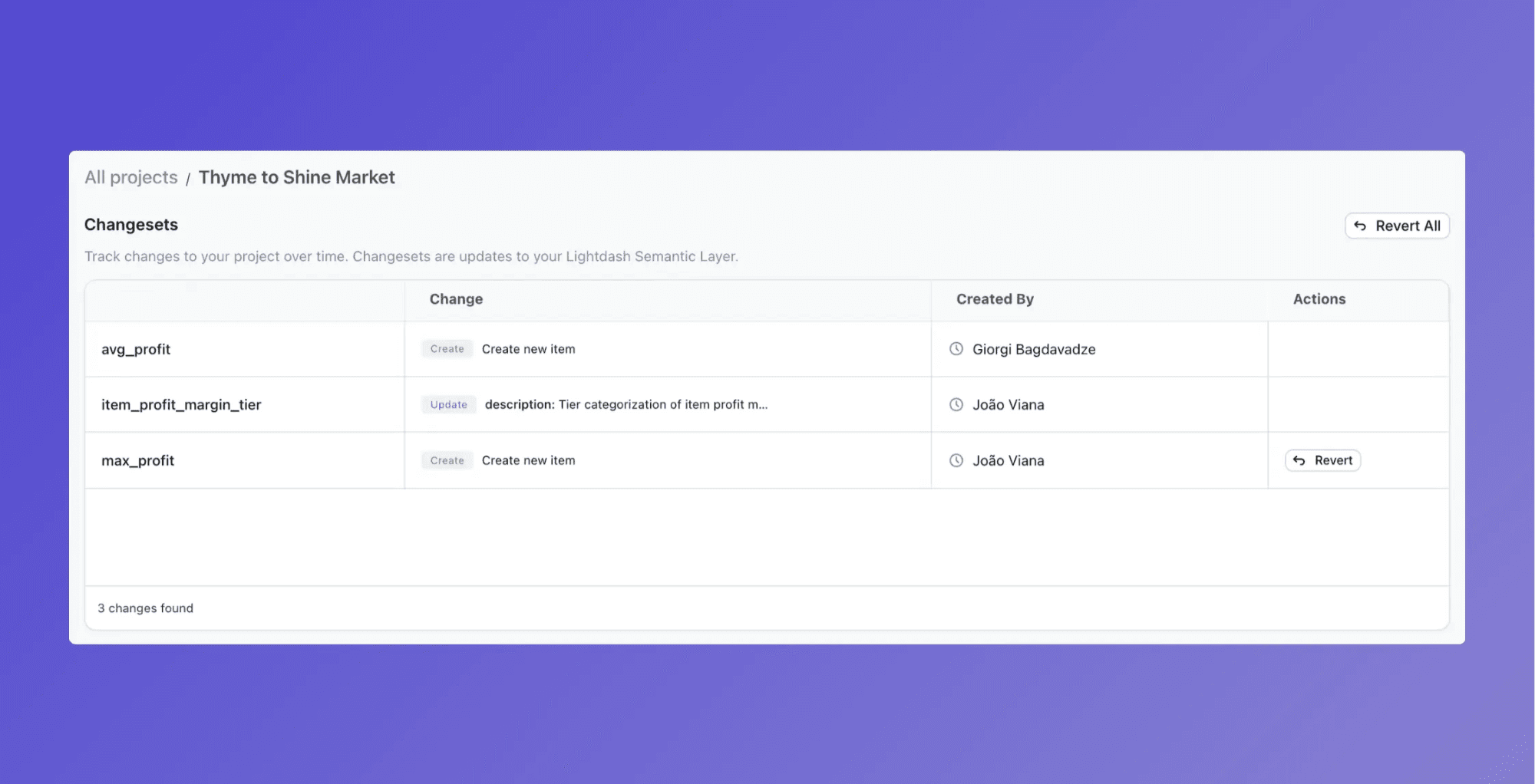
⚡ You stay in control
Only admins and developers can enable self-improvement. You can reject changes directly from the chat interface or revert them from the changesets page. If you redeploy your project, the changeset gets applied if possible, otherwise it's safely ignored.
Why this matters
Most AI agents in BI tools are just chatbots on top of SQL. They translate your questions into queries, which sounds cool until you realize they're generating slightly different SQL every time, with no consistency and no governance.
We built something different because we started with a semantic layer. That means:
Your business logic lives in one place
AI agents work within that governed layer, not around it
When agents improve the semantic layer, every tool using it gets better
The semantic layer is like the rules of the road for self-driving cars. Your AI agents need those guardrails, and when they can help maintain those guardrails themselves, the whole system gets smarter.
The full picture: Lightdash's AI stack
The self-improving semantic layer is part of a bigger bet we're making on AI for BI. Our AI suite includes:
AI agents that answer questions about your data in natural language. They coach users through vague questions, point people to existing dashboards instead of creating duplicates, and now, improve your semantic layer as they go.

Our MCP server which connects AI tools directly to your data. Your LLM can query your semantic layer, create charts, and work with your metrics without you building custom integrations.
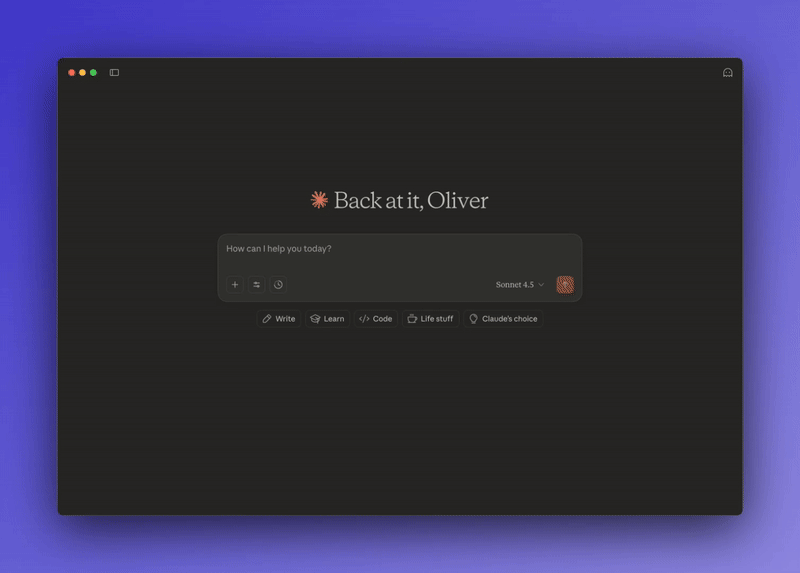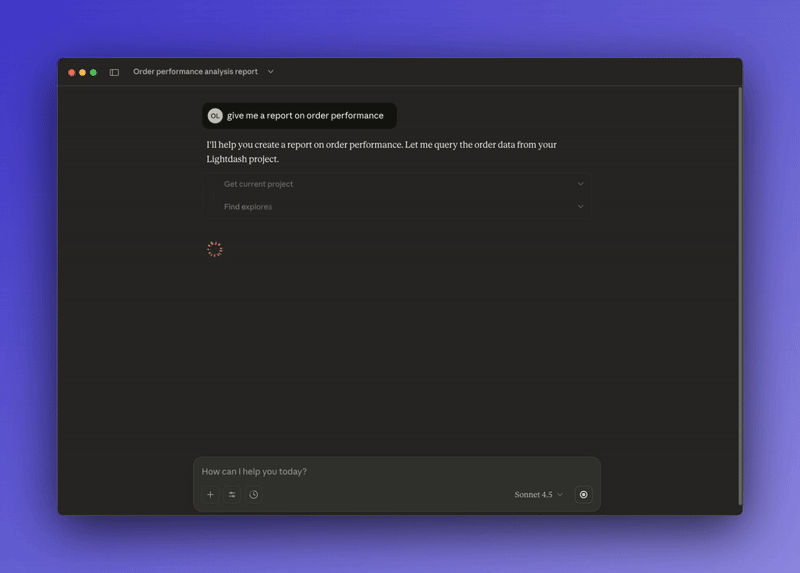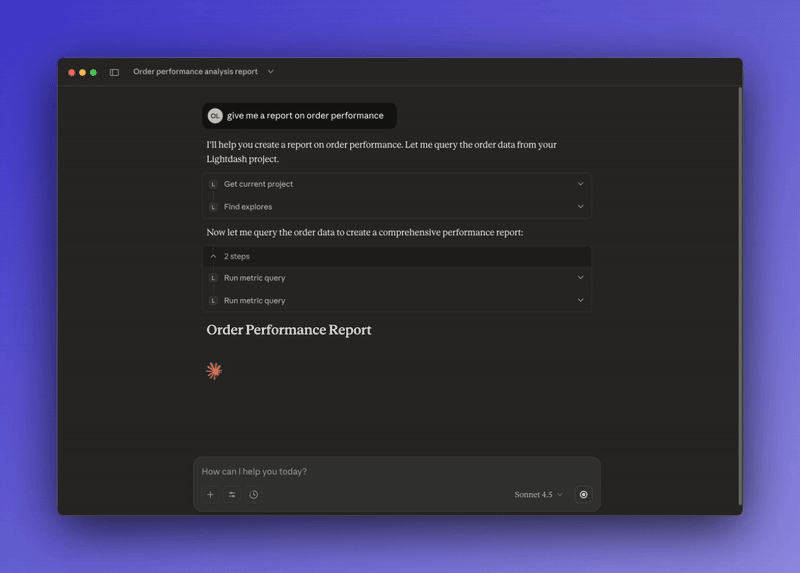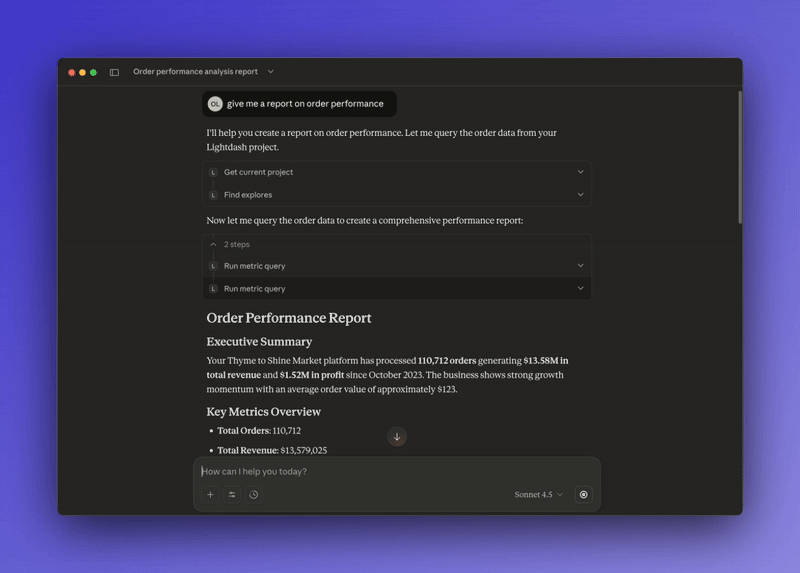
And now, the self-improving semantic layer that gets better over time instead of getting stale.
All of this works together because it's built on the same foundation: a semantic layer that defines your business logic once, and AI that works within those definitions rather than fighting against them.
Try it yourself
Self-improvement is a beta feature right now. If you're already using Lightdash, you can enable it in your agent settings and start testing with your team.
Your data team needs to focus on hard problems instead of constantly updating metric descriptions and creating one-off aggregations. Let the AI handle the repetitive stuff while your humans work on the architecture.
Ready to see it in action? Start your free trial today or check out our docs on self-improvement to learn more.
Ready to free up your data team?
Try out our all in one open, developer-loved platform.